Introduction
CARP(Common Address Redundancy Protocol) is protocol from FHRP(First Hop Redundancy Protocol) family. This protocol is partially based and very similar to VRRP(Virtual Router Redundancy Protocol), is absolutely free and was developed and firstly implemented in OpenBSD project. After some time was CARP rebuilded also for Linux platform. CARP is using same multicast IP like VRRP – 224.0.0.18 just as L2 multicast address – 01:00:5e:00:00:12. Multicast address is used for communication between nodes to negotiate who will be Master/Slave. Main feature of this protocol is to keep floating IP addresses(one or more) between nodes and ensure High Availability access to IP based services.
In our infrastructure we are using CARP as HA solution between Reverse Proxy web front-ends . In combination with Round-Robin DNS and Nginx load-balancer feature, we are using that like robust HA and load-balanced solution for our web sites. Today is very common type of virtualization platform VMware, also we are using VMware virtualization. VMware has many feature which are really useful and decrease need of maintenance windows – of course depends on VMware licence type.
Specific CARP issues in VI
UPDATE: Identical issue detected in case of keepalived that is using VRRP in background
Servers running in VI(Virtual Infrastructure) are generally same like servers running in standalone mode on physical hardware, but here is few specific advantages and disadvantages, as usual. Advantages are for example possibility of snapshots, live migration without maintenance, simple access to console and power management during maintenance, centralized management, live migration of datastores and so on. Disadvantage then can be centralization and service concentration into single point of failure – depends on redundancy design, or less common issues with HA technologies in wider context.
In advance VI is possible to use snapshots for backup VMs. Usually that is not recommended way, but in our infrastructure we are currently testing Veeam enterprise solution which in basic do following. Veeam is creating snapshot of each defined VM(Virtual Machine), this snapshot is copied to different storage and original snapshot is removed. In process of creating and deleting snapshots is possible that VM has inaccessible network arround one or two seconds, depends on number and size of partitions. And that is exactly what can bring on issue. In CARP default configuration is default timer between HELLOs set to 1 second – in case OpenBSD. In case of CentOS Linux isn’t this value specified, it means that value is presented by 0 and advertisement interval(advbase parametr) is then calculated from the following formula:
adv. interval = advskew * 1000000 / 256
advskew define weight of preference to be a master. We have configured for Slave servers advskew to 100. It means that final advertisement interval will be:
100 * 1000000 / 256 = 390625 µs
It means that server is advertising HELLO each 0.39 second. Therefore is presented following situation:
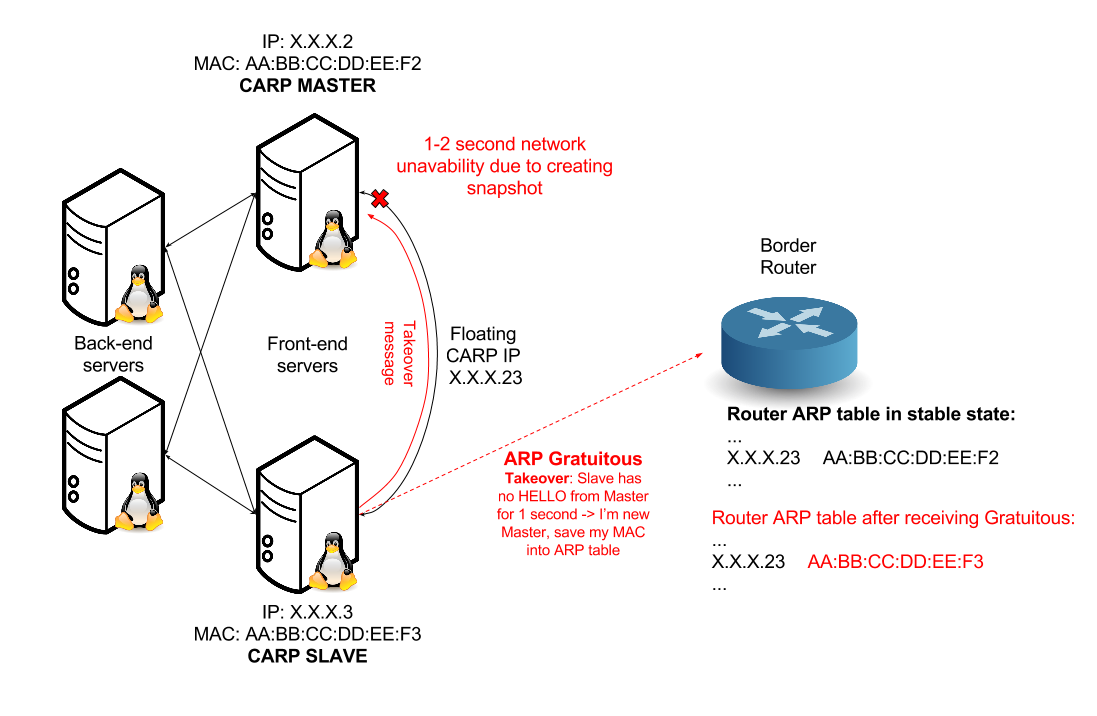
- On Master VM, means master for defined VHDI(Virtual Host ID) group which is primary holder of floating IP address, is Veeam(or admin) creating/deleting snapshot. Network interface of this VM is for one/two seconds inaccessible. It means that master can’t send/receive HELLO
- In this one/two second is Slave not receiving Masters HELLO and therefore is advertising that he is new Master. Slave is sending ARP(Address Resolution Protocol) Gratuitous to inform all machines/routers that he is now holding floating IP. But this ARP Gratuitous is not received on Master because his network interface is temporarily unavailable.
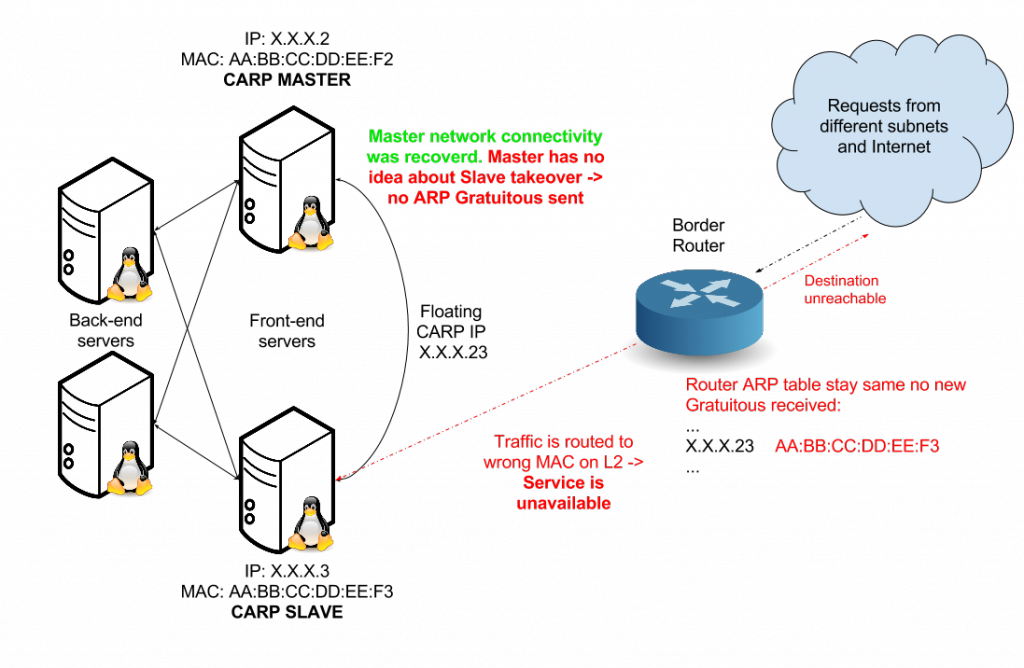
Master recovered - Immediately as soon as is Master network connectivity recovered, Master send HELLO – „I’m a master for this IP address“. Slave is receiving HELLO with higher priority and immediately stop advertising that he is IP holder.
- Problem is that Master had unavailable network connection and therefore he didn’t know about Slave takeover. Therefore isn’t advertising that he is back main holder of floating IP and isn’t sending ARP Gratuitous.
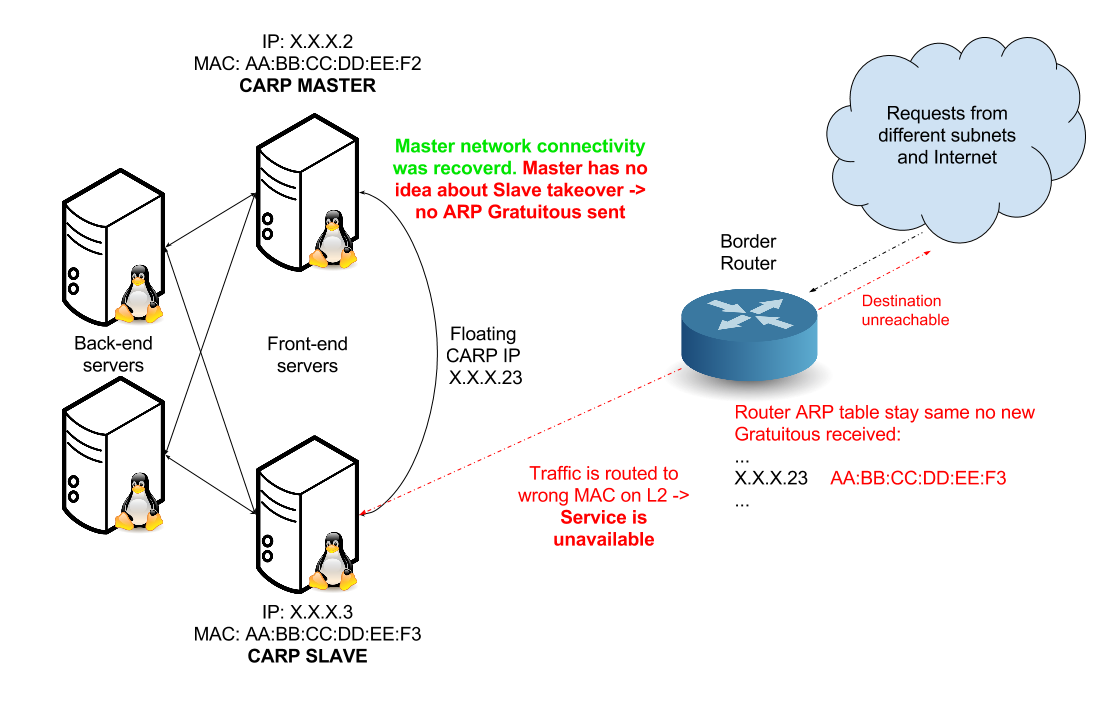
So, that’s all. Do you know what is going wrong now?
Other VMs in same IP subnet like front-ends are not impacted because before starting IP communication they are sending ARP request and receive reply with correct MAC(Media Access Control) address. But routers are usually caching ARP records(up to 240 minutes) until they obtain new ARP Gratuitous to update his record, or this record is expired. That’s the point of failure because Master didn’t send ARP Gratuitous because he didn’t obtain takeover from Slave due to unavailable network. Final state is, that traffic is routed to Slave MAC on Layer 2 and router think that IP is unreachable.
Here is sample of /var/log/messages focused to CARP logging:
Nov 9 08:04:47 hostname ucarp[8656]: [WARNING] Switching to state: MASTER Nov 9 08:04:47 hostname ucarp[8639]: [WARNING] Spawning [/etc/sysconfig/carp/vip-up eth0:0 X.X.X.23] Nov 9 08:04:47 hostname ucarp[8656]: [WARNING] Switching to state: BACKUP Nov 9 08:04:47 hostname ucarp[8656]: [WARNING] Spawning [/etc/sysconfig/carp/vip-down eth0:0 X.X.X.23] Nov 9 08:04:47 hostname ucarp[8639]: [WARNING] Preferred master advertised: going back to BACKUP state
You can see above that switching between Master and Slave on the Slave VM was really performed in one second. That is usually undesirable for majority deployments.
Solution
Solution is pretty simple. Keep in mind that advbase parameter should be always specified. It means, if is not defined in configuration file then should be configured to default value 1 second to avoid this unexpected behaviour described above.
Good luck with CARP,
Josef